PDE-constrained optimization with neural network chemical potential
In this notebook, we show how to use the PDEModel class to perform PDE-constrained optimization with a neural network parameterization.
We will use a neural network to represent the non-gradient part of the chemical potential.
[1]:
import jax
import jax.numpy as jnp
import matplotlib.pyplot as plt
import pde_opt
from pde_opt.pde_model import PDEModel
from pde_opt.numerics.equations.cahn_hilliard import CahnHilliard2DPeriodic
from pde_opt.numerics.solvers import SemiImplicitFourierSpectral
from pde_opt.numerics.domains import Domain
from pde_opt.numerics.functions.cnn import PeriodicCNN
import equinox as eqx
We will first create the domain for the PDE. We choose to use a small domain so the code runs in a reasonable amount of time in the notebook.
[2]:
Nx = Ny = 32
Lx = Ly = 0.01 * Nx
domain = Domain(
(Nx, Ny),
(
(-Lx / 2, Lx / 2),
(-Ly / 2, Ly / 2),
),
"dimensionless",
)
Constructing the PDE model for optimization just involves specifying the equation, domain, and time stepping method.
[3]:
opt_model = PDEModel(
equation_type=CahnHilliard2DPeriodic,
domain=domain,
solver_type=SemiImplicitFourierSpectral,
)
Here, we set parameter values for the terms in the Cahn-Hilliard equation. These parameters will serve as our “ground truth”, which we will try to recover in our optimization. In this example, we only focus on learning the chemical potential.
[4]:
params = {"kappa": 0.002, "mu": lambda c: jnp.log(c / (1.0 - c)) + 3.0 * (1.0 - 2.0 * c), "D": lambda c: jnp.ones_like(c)}
solver_params = {"A": 0.5}
Now we can solve the system with the parameters to get the training dataset we will use in the optimization.
[5]:
key = jax.random.PRNGKey(0)
y0 = jnp.clip(0.01 * jax.random.normal(key, (Nx, Ny)) + 0.5, 0.0, 1.0)
ts = jnp.linspace(0.0, 0.02, 100)
sol = opt_model.solve(params, y0, ts, solver_params, dt0=0.000001, max_steps=1000000)
We can visualize what this solution looks like.
[6]:
fig, ax = plt.subplots(1, 5)
ax[0].imshow(sol[0], vmin=0.0, vmax=1.0)
ax[0].set_title(f"t = {ts[0]:.3f}")
ax[1].imshow(sol[10], vmin=0.0, vmax=1.0)
ax[1].set_title(f"t = {ts[10]:.3f}")
ax[2].imshow(sol[20], vmin=0.0, vmax=1.0)
ax[2].set_title(f"t = {ts[20]:.3f}")
ax[3].imshow(sol[50], vmin=0.0, vmax=1.0)
ax[3].set_title(f"t = {ts[50]:.3f}")
ax[4].imshow(sol[-1], vmin=0.0, vmax=1.0)
ax[4].set_title(f"t = {ts[-1]:.3f}")
plt.tight_layout()
plt.show()
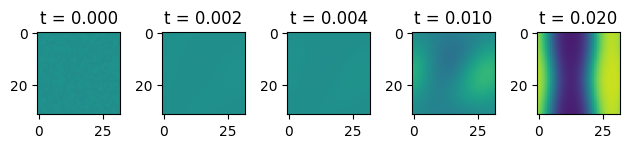
We will use a CNN to represent the non-gradient part of the chemical potential term in the Cahn-Hilliard equation.
This CNN is set up with circular padding to properly account for the periodic boundary conditions of the simulation. It also uses same padding to return an array of the same shape as the input. With a stride of 1, it is perfectly translationally equivariant (since the padding is circular, it is specifically translationally equivariant on a torus).
[7]:
model = PeriodicCNN(
in_channels=1,
hidden_channels=(32, 64, 64),
out_channels=1,
kernel_size=3,
key=jax.random.PRNGKey(0),
)
model = eqx.filter_jit(model)
The train function expects the data is passed in as a dictionary with the time points specified in the ‘ts’ key and the fields specified in the ‘ys’ key.
We must also pass in a list of lists indicating which indices we want to include in the simulation. Each inner list has the following format: [starting time, time to evaluate loss, time to evaluate loss, …., final time to evaluate loss]. When computing the total loss, we vmap over each list and average.
You can also experiment with adding noise to the data. For this example, we don’t add noise to speed up the optimization process, but the method is robust to certain levels of noise.
[8]:
data = {}
data['ys'] = sol
data['ts'] = ts
inds = [[30,40,50], [50,60,70], [70,80,90]]
Now we need an initial set of parameters at which to start the optimization at. For the chemical potential, our initial parameters are the CNN model we defined above. This is a nice part of using Equinox to create our neural networks, as the whole model is represented as a PyTree, and we can use filtered operations like JIT and grad to properly extract the arrays, or use partition and combine operations to separate the array and non-array leaves. We can therefore pass full equinox models as “parameters” in our equation, which makes the interface much more general and easier to use.
We put the parameters or models we wish to optimize over in a separate dictionary than the parameters that we wish to remain fixed/static. Finally, we can regularize the parameters using a weights dictionary. This dictionary must match the structure of the optimization parameters dictionary, and the PyTrees for each key must have the same structure. Then we can use tree_map and tree_reduce to compute the regularization term. The lambda_reg is then a global scale factor applied to every regularization term.
[9]:
init_params = {
"mu": model,
}
static_params = {
"kappa": 0.002,
"D": lambda c: jnp.ones_like(c),
}
solver_parameters = {
"A": 0.5,
}
weights = {
"mu": None
}
lambda_reg = 0.0
Let’s now visualize what the initial solution looks like for our starting guess of chemical potential. Note that there is no phase separation!
[10]:
test_sol = opt_model.solve({**init_params, **static_params}, y0, ts, solver_parameters, dt0=0.000001, max_steps=1000000)
fig, ax = plt.subplots(1, 5)
ax[0].imshow(test_sol[0], vmin=0.0, vmax=1.0)
ax[1].imshow(test_sol[10], vmin=0.0, vmax=1.0)
ax[2].imshow(test_sol[20], vmin=0.0, vmax=1.0)
ax[3].imshow(test_sol[50], vmin=0.0, vmax=1.0)
ax[4].imshow(test_sol[-1], vmin=0.0, vmax=1.0)
plt.tight_layout()
plt.show()
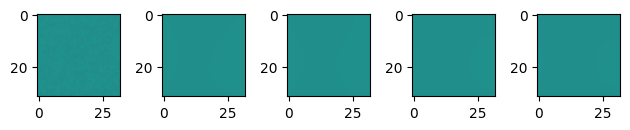
We can now pass in the dataset, the optimization indices, the parameters we want to fit, the static parameters, and the regularization weights into the train function. This should take around 4 minutes per 100 steps and the results will be improved for more steps.
[11]:
res = opt_model.train(data, inds, init_params, static_params, solver_parameters, weights, lambda_reg, method="mse", max_steps=100)
Loss on this step: 0.02575879916548729, Loss on the last accepted step: 0.0, Step size: 1.0
Loss on this step: 0.024840211495757103, Loss on the last accepted step: 0.02575879916548729, Step size: 1.0
Loss on this step: 0.023725321516394615, Loss on the last accepted step: 0.024840211495757103, Step size: 1.0
Loss on this step: 0.02216164395213127, Loss on the last accepted step: 0.023725321516394615, Step size: 1.0
Loss on this step: 0.01957777701318264, Loss on the last accepted step: 0.02216164395213127, Step size: 1.0
Loss on this step: 0.014478474855422974, Loss on the last accepted step: 0.01957777701318264, Step size: 1.0
Loss on this step: 0.013381581753492355, Loss on the last accepted step: 0.014478474855422974, Step size: 1.0
Loss on this step: 0.012342186644673347, Loss on the last accepted step: 0.013381581753492355, Step size: 0.5
Loss on this step: 0.009633365087211132, Loss on the last accepted step: 0.013381581753492355, Step size: 1.0
Loss on this step: 0.009363628923892975, Loss on the last accepted step: 0.009633365087211132, Step size: 1.0
Loss on this step: 0.008917927742004395, Loss on the last accepted step: 0.009363628923892975, Step size: 1.0
Loss on this step: 0.008701509796082973, Loss on the last accepted step: 0.008917927742004395, Step size: 1.0
Loss on this step: 0.008083686232566833, Loss on the last accepted step: 0.008701509796082973, Step size: 1.0
Loss on this step: 0.007947399280965328, Loss on the last accepted step: 0.008083686232566833, Step size: 1.0
Loss on this step: 0.00785524956882, Loss on the last accepted step: 0.007947399280965328, Step size: 1.0
Loss on this step: 0.00768642034381628, Loss on the last accepted step: 0.00785524956882, Step size: 1.0
Loss on this step: 0.007624085061252117, Loss on the last accepted step: 0.00768642034381628, Step size: 1.0
Loss on this step: 0.0075124045833945274, Loss on the last accepted step: 0.007624085061252117, Step size: 1.0
Loss on this step: 0.0074628740549087524, Loss on the last accepted step: 0.0075124045833945274, Step size: 1.0
Loss on this step: 0.007126289885491133, Loss on the last accepted step: 0.0074628740549087524, Step size: 1.0
Loss on this step: 0.00653224578127265, Loss on the last accepted step: 0.007126289885491133, Step size: 1.0
Loss on this step: 0.00563008664175868, Loss on the last accepted step: 0.00653224578127265, Step size: 1.0
Loss on this step: 0.004209394566714764, Loss on the last accepted step: 0.00563008664175868, Step size: 1.0
Loss on this step: 0.009180955588817596, Loss on the last accepted step: 0.004209394566714764, Step size: 0.5
Loss on this step: 0.004683034494519234, Loss on the last accepted step: 0.004209394566714764, Step size: 0.25
Loss on this step: 0.003886689431965351, Loss on the last accepted step: 0.004209394566714764, Step size: 1.0
Loss on this step: 0.010074438527226448, Loss on the last accepted step: 0.003886689431965351, Step size: 0.5
Loss on this step: 0.004526447504758835, Loss on the last accepted step: 0.003886689431965351, Step size: 0.25
Loss on this step: 0.003344346536323428, Loss on the last accepted step: 0.003886689431965351, Step size: 1.0
Loss on this step: 0.0022445842623710632, Loss on the last accepted step: 0.003344346536323428, Step size: 1.0
Loss on this step: 0.03795602545142174, Loss on the last accepted step: 0.0022445842623710632, Step size: 0.5
Loss on this step: 0.0032787355594336987, Loss on the last accepted step: 0.0022445842623710632, Step size: 0.25
Loss on this step: 0.0017620989819988608, Loss on the last accepted step: 0.0022445842623710632, Step size: 1.0
Loss on this step: 0.004334747325628996, Loss on the last accepted step: 0.0017620989819988608, Step size: 0.5
Loss on this step: 0.001577726099640131, Loss on the last accepted step: 0.0017620989819988608, Step size: 1.0
Loss on this step: 0.001072277082130313, Loss on the last accepted step: 0.001577726099640131, Step size: 1.0
Loss on this step: 0.000834881269838661, Loss on the last accepted step: 0.001072277082130313, Step size: 1.0
Loss on this step: 0.0006369617185555398, Loss on the last accepted step: 0.000834881269838661, Step size: 1.0
Loss on this step: 0.0006082485197111964, Loss on the last accepted step: 0.0006369617185555398, Step size: 1.0
Loss on this step: 0.0004931482835672796, Loss on the last accepted step: 0.0006082485197111964, Step size: 1.0
Loss on this step: 0.0004595555365085602, Loss on the last accepted step: 0.0004931482835672796, Step size: 1.0
Loss on this step: 0.000443166441982612, Loss on the last accepted step: 0.0004595555365085602, Step size: 1.0
Loss on this step: 0.0004167730803601444, Loss on the last accepted step: 0.000443166441982612, Step size: 1.0
Loss on this step: 0.00036184792406857014, Loss on the last accepted step: 0.0004167730803601444, Step size: 1.0
Loss on this step: 0.00032458052737638354, Loss on the last accepted step: 0.00036184792406857014, Step size: 1.0
Loss on this step: 0.0003079049929510802, Loss on the last accepted step: 0.00032458052737638354, Step size: 1.0
Loss on this step: 0.00029907189309597015, Loss on the last accepted step: 0.0003079049929510802, Step size: 1.0
Loss on this step: 0.00029348526732064784, Loss on the last accepted step: 0.00029907189309597015, Step size: 1.0
Loss on this step: 0.00028728513279929757, Loss on the last accepted step: 0.00029348526732064784, Step size: 1.0
Loss on this step: 0.0002827902790158987, Loss on the last accepted step: 0.00028728513279929757, Step size: 1.0
Loss on this step: 0.000276821170700714, Loss on the last accepted step: 0.0002827902790158987, Step size: 1.0
Loss on this step: 0.0002732997527346015, Loss on the last accepted step: 0.000276821170700714, Step size: 1.0
Loss on this step: 0.0002687609812710434, Loss on the last accepted step: 0.0002732997527346015, Step size: 1.0
Loss on this step: 0.0002733277506195009, Loss on the last accepted step: 0.0002687609812710434, Step size: 0.5
Loss on this step: 0.00026512809563428164, Loss on the last accepted step: 0.0002687609812710434, Step size: 1.0
Loss on this step: 0.0002584511530585587, Loss on the last accepted step: 0.00026512809563428164, Step size: 1.0
Loss on this step: 0.00024318524810951203, Loss on the last accepted step: 0.0002584511530585587, Step size: 1.0
Loss on this step: 0.0002366634871577844, Loss on the last accepted step: 0.00024318524810951203, Step size: 1.0
Loss on this step: 0.005694050341844559, Loss on the last accepted step: 0.0002366634871577844, Step size: 0.5
Loss on this step: 0.0006690174341201782, Loss on the last accepted step: 0.0002366634871577844, Step size: 0.25
Loss on this step: 0.00025894143618643284, Loss on the last accepted step: 0.0002366634871577844, Step size: 0.125
Loss on this step: 0.00023088790476322174, Loss on the last accepted step: 0.0002366634871577844, Step size: 1.0
Loss on this step: 0.00021556857973337173, Loss on the last accepted step: 0.00023088790476322174, Step size: 1.0
Loss on this step: 0.00021566986106336117, Loss on the last accepted step: 0.00021556857973337173, Step size: 0.5
Loss on this step: 0.00021010692580603063, Loss on the last accepted step: 0.00021556857973337173, Step size: 1.0
Loss on this step: 0.0002081922721117735, Loss on the last accepted step: 0.00021010692580603063, Step size: 1.0
Loss on this step: 0.00020170136122033, Loss on the last accepted step: 0.0002081922721117735, Step size: 1.0
Loss on this step: 0.0001973663893295452, Loss on the last accepted step: 0.00020170136122033, Step size: 1.0
Loss on this step: 0.00019680371042340994, Loss on the last accepted step: 0.0001973663893295452, Step size: 0.5
Loss on this step: 0.00019176153000444174, Loss on the last accepted step: 0.0001973663893295452, Step size: 1.0
Loss on this step: 0.00018611147243063897, Loss on the last accepted step: 0.00019176153000444174, Step size: 1.0
Loss on this step: 0.00018013808585237712, Loss on the last accepted step: 0.00018611147243063897, Step size: 1.0
Loss on this step: 0.00021688219567295164, Loss on the last accepted step: 0.00018013808585237712, Step size: 0.5
Loss on this step: 0.00017903404659591615, Loss on the last accepted step: 0.00018013808585237712, Step size: 1.0
Loss on this step: 0.00017550114716868848, Loss on the last accepted step: 0.00017903404659591615, Step size: 1.0
Loss on this step: 0.00017349462723359466, Loss on the last accepted step: 0.00017550114716868848, Step size: 1.0
Loss on this step: 0.0001818201271817088, Loss on the last accepted step: 0.00017349462723359466, Step size: 0.5
Loss on this step: 0.0001702978042885661, Loss on the last accepted step: 0.00017349462723359466, Step size: 1.0
Loss on this step: 0.00016702954599168152, Loss on the last accepted step: 0.0001702978042885661, Step size: 1.0
Loss on this step: 0.00016017338202800602, Loss on the last accepted step: 0.00016702954599168152, Step size: 1.0
Loss on this step: 0.00015449049533344805, Loss on the last accepted step: 0.00016017338202800602, Step size: 1.0
Loss on this step: 0.00015312717005144805, Loss on the last accepted step: 0.00015449049533344805, Step size: 1.0
Loss on this step: 0.00015218736371025443, Loss on the last accepted step: 0.00015312717005144805, Step size: 1.0
Loss on this step: 0.00015097871073521674, Loss on the last accepted step: 0.00015218736371025443, Step size: 1.0
Loss on this step: 0.00014900413225404918, Loss on the last accepted step: 0.00015097871073521674, Step size: 1.0
Loss on this step: 0.000143011289765127, Loss on the last accepted step: 0.00014900413225404918, Step size: 1.0
Loss on this step: 0.0001297083217650652, Loss on the last accepted step: 0.000143011289765127, Step size: 1.0
Loss on this step: 0.0001221512648044154, Loss on the last accepted step: 0.0001297083217650652, Step size: 1.0
Loss on this step: 0.0001200494880322367, Loss on the last accepted step: 0.0001221512648044154, Step size: 1.0
Loss on this step: 0.00011886139691341668, Loss on the last accepted step: 0.0001200494880322367, Step size: 1.0
Loss on this step: 0.00011792720761150122, Loss on the last accepted step: 0.00011886139691341668, Step size: 1.0
Loss on this step: 0.00011726199591066688, Loss on the last accepted step: 0.00011792720761150122, Step size: 1.0
Loss on this step: 0.00011667841317830607, Loss on the last accepted step: 0.00011726199591066688, Step size: 1.0
Loss on this step: 0.00011586620530579239, Loss on the last accepted step: 0.00011667841317830607, Step size: 1.0
Loss on this step: 0.00011410089064156637, Loss on the last accepted step: 0.00011586620530579239, Step size: 1.0
Loss on this step: 0.00011136519606225193, Loss on the last accepted step: 0.00011410089064156637, Step size: 1.0
Loss on this step: 0.00010749819921329618, Loss on the last accepted step: 0.00011136519606225193, Step size: 1.0
Loss on this step: 0.0001045748358592391, Loss on the last accepted step: 0.00010749819921329618, Step size: 1.0
Loss on this step: 0.0001034553861245513, Loss on the last accepted step: 0.0001045748358592391, Step size: 1.0
Loss on this step: 0.000103585327451583, Loss on the last accepted step: 0.0001034553861245513, Step size: 0.5
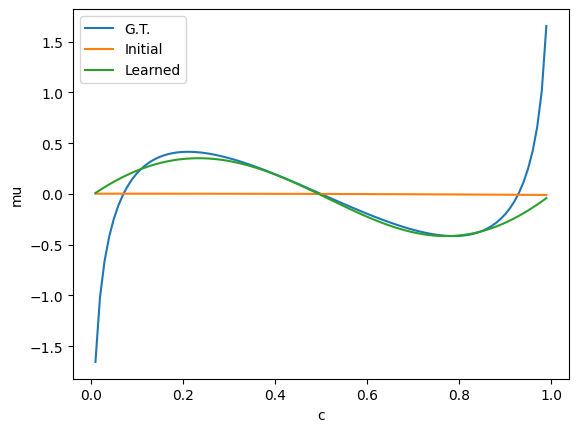
Finally, we can see that our learned chemical potential matches the ground truth chemical potential.
[12]:
cs = jnp.linspace(0.01, 0.99, 100)
c_gt = params['mu'](cs)
c_nn_init = []
c_nn = []
for c in cs:
c_nn_init.append(jnp.mean(init_params['mu'](c * jnp.ones_like(y0))))
c_nn.append(jnp.mean(res['mu'](c * jnp.ones_like(y0))))
# Shift c_nn to make value at c=0.5 zero
c_nn_array = jnp.array(c_nn)
c_nn_init_array = jnp.array(c_nn_init)
idx_05 = jnp.argmin(jnp.abs(cs - 0.5)) # Find index closest to c=0.5
shift = c_nn_array[idx_05]
shift_init = c_nn_init_array[idx_05]
c_nn = c_nn_array - shift
c_nn_init = c_nn_init_array - shift_init
fig, ax = plt.subplots(1, 1)
ax.plot(cs, c_gt, label='G.T.')
ax.plot(cs, c_nn_init, label='Initial')
ax.plot(cs, c_nn, label='Learned')
ax.set_xlabel('c')
ax.set_ylabel('mu')
ax.legend()
plt.show()
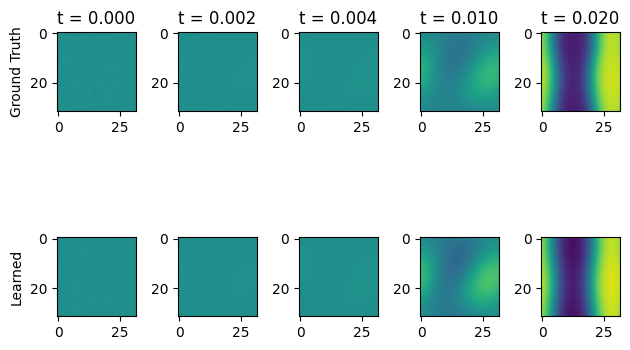
And we can use this chemical potential to simulate the full PDE and compare with the ground truth simulation.
[13]:
opt_sol = opt_model.solve(res, y0, ts, solver_parameters, dt0=0.000001, max_steps=1000000)
fig, ax = plt.subplots(2, 5)
ax[0,0].imshow(sol[0], vmin=0.0, vmax=1.0)
ax[0,0].set_ylabel("Ground Truth")
ax[0,0].set_title(f"t = {ts[0]:.3f}")
ax[0,1].imshow(sol[10], vmin=0.0, vmax=1.0)
ax[0,1].set_title(f"t = {ts[10]:.3f}")
ax[0,2].imshow(sol[20], vmin=0.0, vmax=1.0)
ax[0,2].set_title(f"t = {ts[20]:.3f}")
ax[0,3].imshow(sol[50], vmin=0.0, vmax=1.0)
ax[0,3].set_title(f"t = {ts[50]:.3f}")
ax[0,4].imshow(sol[-1], vmin=0.0, vmax=1.0)
ax[0,4].set_title(f"t = {ts[-1]:.3f}")
ax[1,0].imshow(opt_sol[0], vmin=0.0, vmax=1.0)
ax[1,0].set_ylabel("Learned")
ax[1,1].imshow(opt_sol[10], vmin=0.0, vmax=1.0)
ax[1,2].imshow(opt_sol[20], vmin=0.0, vmax=1.0)
ax[1,3].imshow(opt_sol[50], vmin=0.0, vmax=1.0)
ax[1,4].imshow(opt_sol[-1], vmin=0.0, vmax=1.0)
plt.tight_layout()
plt.show()
[ ]: